K-Means Clustering Algorithm
K-Means Clustering
K-Means Clustering adalah salah satu algoritma dalam menentukan klasifikasi terhadap objek berdasarkan attribut / fitur dari objek tersebut kedalam K kluster/partisi. K adalah angka positif yang menyatakan jumlah grup/kluster/partisi terhadap objek. Pemartisian data dilakukan dengan mencari nilai jarak minimum antara data dan nilai centroid yang telah di set baik secara random atau pun dengan Initial Set of Centroids, kita juga dapat menentukan nilai centroid berdasarkan K object yang berurutan.
Centroid adalah nilai rata-rata aritmetik dari sebuah bentuk objek dari seluruh titik dalam objek tersebut. Penerapan K-Means Clustering ini dapat dilakukan dengan prosedur step by step berikut :
 Contoh penerapan K-Means Cluster
Contoh penerapan K-Means Cluster
| Data | Attribut / fitur | |
| X | Y | |
| A | 5,09 | 5,80 |
| B | 3,24 | 5,90 |
| C | 1,68 | 4,90 |
| D | 1,00 | 3,17 |
| E | 1,48 | 1,38 |
| F | 2,91 | 0,20 |
| G | 4,76 | 0,10 |
| H | 6,32 | 1,10 |
| I | 7,00 | 2,83 |
| J | 6,52 | 4,62 |
Akan dilakukan pemartisian data terhadap data diatas sebanyak 2 partisi, maka tahapannya dalah sebagai berikut :
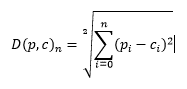 dimana p adalah data, c adalah centroid, n adalah jumlah data, i adalah iterasi.
dimana p adalah data, c adalah centroid, n adalah jumlah data, i adalah iterasi.
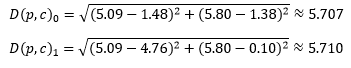
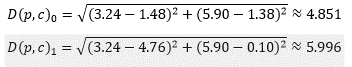
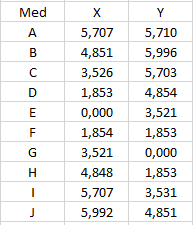
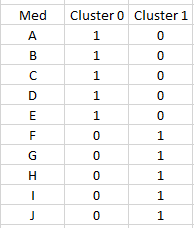 Contoh pada A, X = 5.707 lebih kecil dari Y = 5.710, maka A termasuk ke dalam Cluster 0. Begitu juga dengan F, X = 1.854 lebih besar dari Y = 1.853, maka B masuk ke dalam Cluster 1.
Contoh pada A, X = 5.707 lebih kecil dari Y = 5.710, maka A termasuk ke dalam Cluster 0. Begitu juga dengan F, X = 1.854 lebih besar dari Y = 1.853, maka B masuk ke dalam Cluster 1.

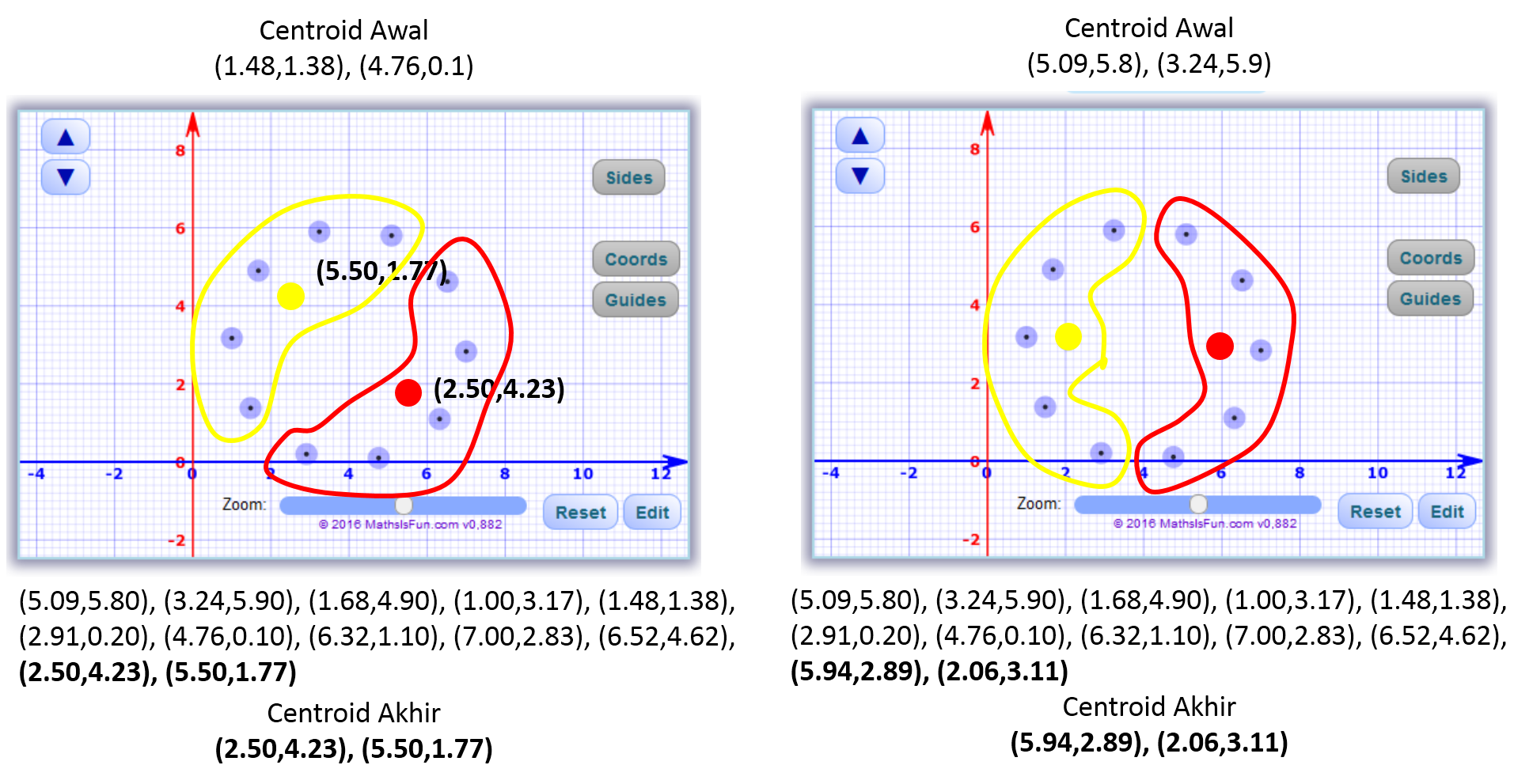
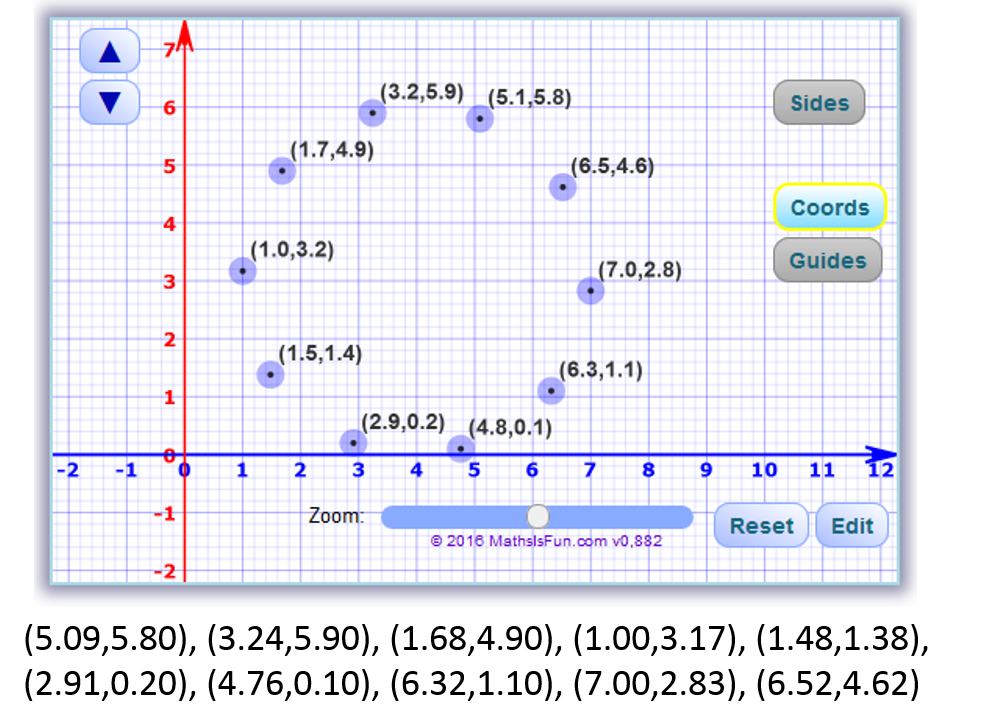
Berikut adalah tampilan kordinat cartesius dari sample data diatas :
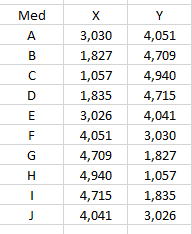
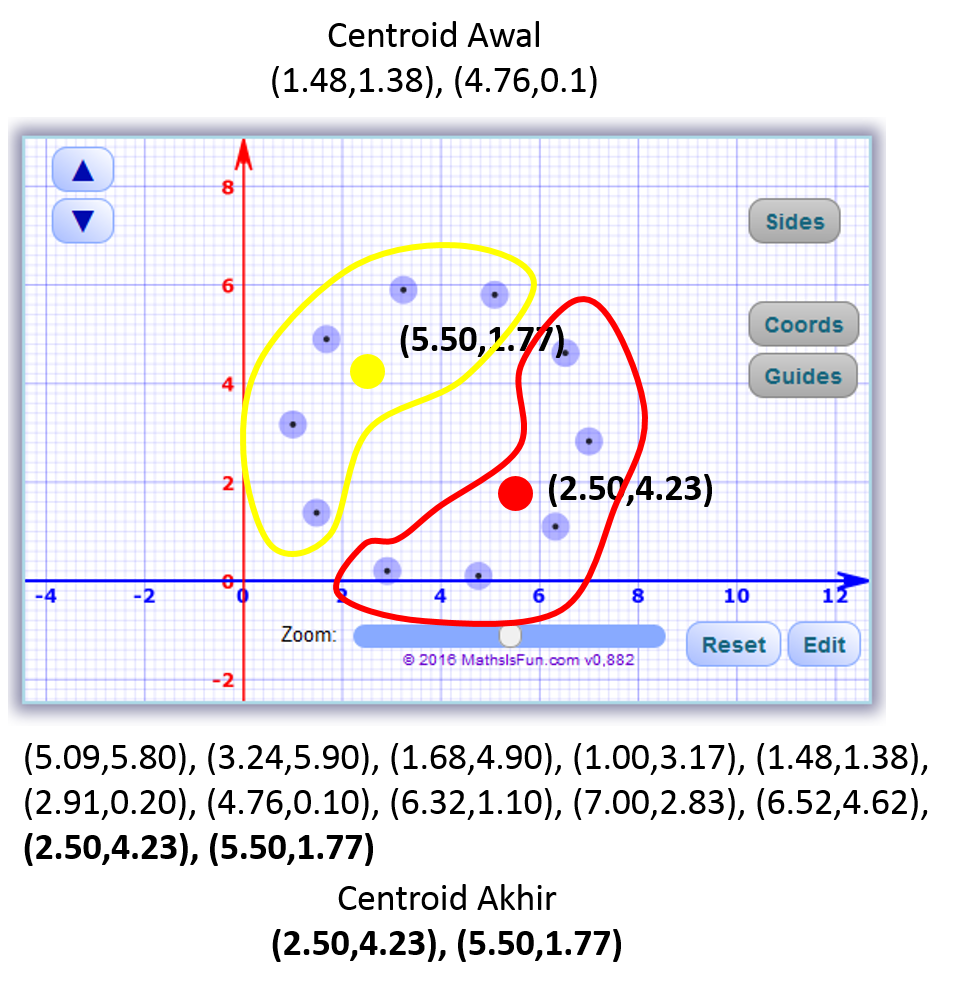
Berikut adalah tampilan setelah penerapan K-Means Clustering dengan centroid akhir:
Aplikasi K-Means Clustering sangat sering digunakan, mulai dari unsupervised learning of neural network, Pattern Recognitions, Classifications Analysis, Artificial Intelligence, Image Processing, Computer Vision dan banyak lainnya.
Berikut adalah penerapan K-Means Clustering pada Bahasa Pemrograman JavaScript (spidermonkey). Sample Test Program !!!
Apabila ada yang ingin didiskusikan, silahkan isi komentar yak. Sampai jumpa di artikel selanjutnya.
Source Code : https://github.com/ekojs/machine_learning/blob/master/unsupervised/ejs_kmeans.js
Sumber :
- https://en.wikipedia.org/wiki/K-means_clustering
- http://people.revoledu.com/kardi/tutorial/kMean/NumericalExample.htm
- http://mnemstudio.org/clustering-k-means-introduction.htm